Telegram is down (again): a deep look at their infrastructure
I’ve been a strong Telegram advocate since its launch in 2013, mainly because of the advanced features and technical state of the art compared to competitors – as a consequence, I’ve been looking very closely at their infrastructure for the last few years.
The two large scale outages that recently hit their users and the sequence of events following them made me ask some questions around their platform. For most of them I have only found additional question marks rather than answers, but here it is what I have so far.
Let’s start from the outages: in case you missed that, on March 29th and April 29th this year, Telegram went down in their Amsterdam datacenter due to a power failure, causing disruptions, according to their official communications, to users in EMEA, MENA, Russia and CIS.
Power outage at a @telegram server cluster causing issues in Europe. Working to fix it from our side, but a lot depends on when the datacenter provider puts the power equipment in order.
— Pavel Durov (@durov) March 29, 2018
Repairs are ongoing after a massive power outage in the Amsterdam region that affected many services. Telegram users in Europe, MENA, Russia and the CIS are currently unable to connect. We apologize and will update you on the progress. https://t.co/WyfYimZoKV
— Telegram Messenger (@telegram) April 29, 2018
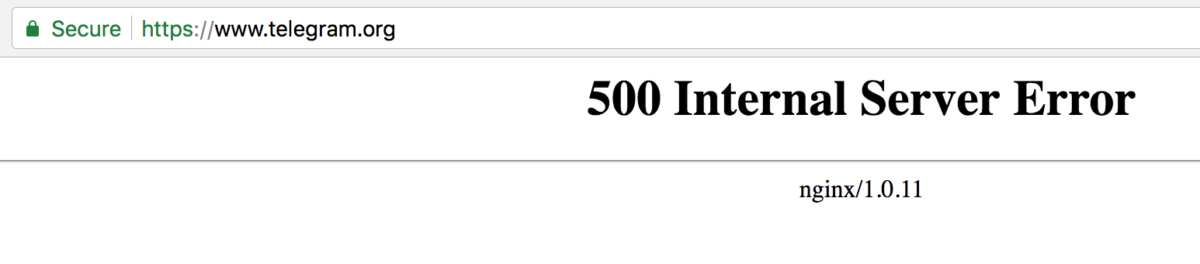
Zooming in on the latter: it’s still ongoing at time of writing this article (8:30AM UTC), and is showing up with clients unable to connect to the platform and both https://www.telegram.org/ (website) and https://api.telegram.org/ (api endpoint) failing with an HTTP error code 500.
Let’s start with the items that, to me, don’t add up: first and foremost, the outage. In case of “massive power outage” in the Amsterdam area, I would expect to see a traffic drop in AMS-IX, the largest Internet Exchange in the region, but there is none (it should be showing around 01 AM):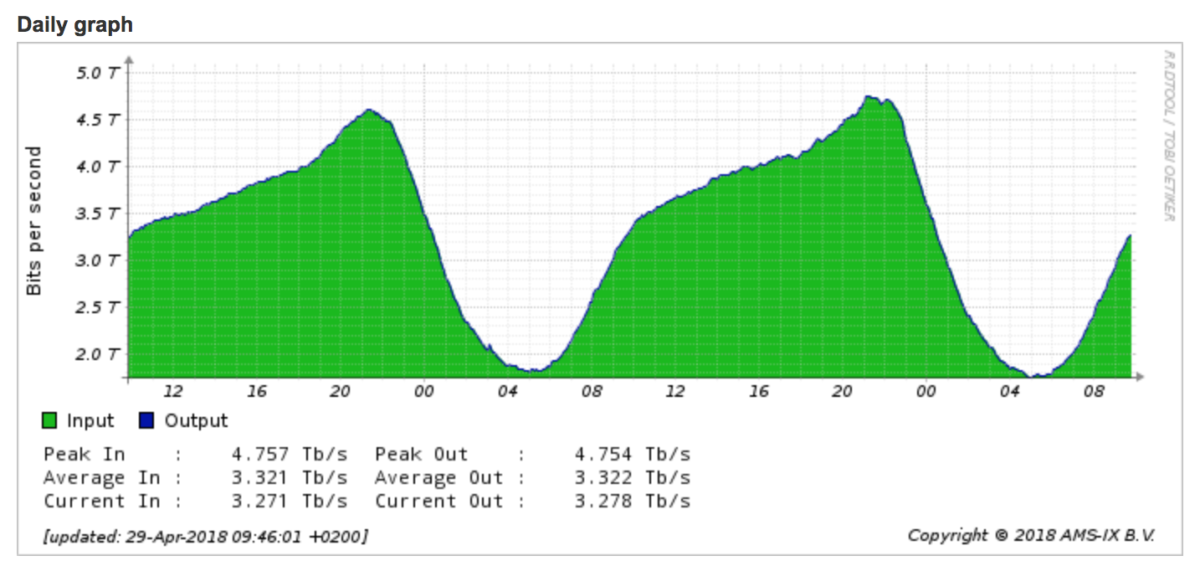
There are indeed reports of an outage that affected Amsterdam (below the one from Schiphol Airport), but no (public) reports of consequent large datacenter failures.

Who’s involved in running large scale platforms will be surprised by at least two things here: the fact that they are serving an huge geographical area from a single datacenter and their inability to reactively reroute traffic to the other locations they are operating, even in case of extended outage (no DR plans?).
A quick search on Twitter shows that even if the official communication states the issue is only affecting the EMEA region, users from Canada, US, Australia, Japan and other countries are facing it as well.
I used Host-Tracker to have a deeper look into this: an HTTP check to Telegram’s API endpoint and their website fails with an HTTP 500 error from every location across the world:
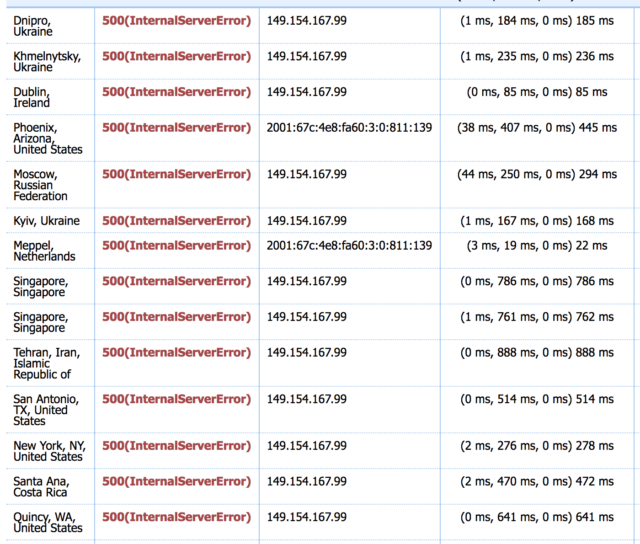
I went ahead and began digging to find out more about their infrastructure, network and the other locations they are running from.
And here comes the second huge question mark: the infrastructure.
A bunch of DNS lookups across the main endpoints show they are always resolving to the same v4 and v6 IPs, in a way that doesn’t look related to the source location of my queries.
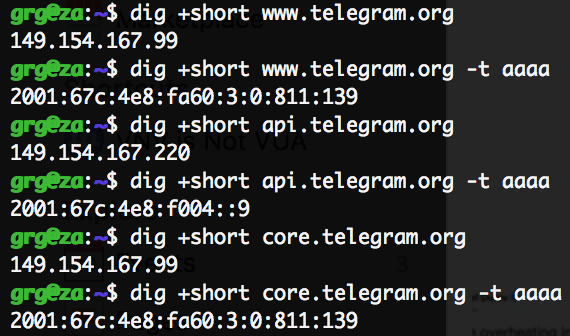
They look to be announced by AS62041 (owned by Telegram LLP): this kind of DNS scheme made me think they were running an anycast based network, so next logical step has been analysing latencies from multiple locations.
Turns out, latency is averaging 20/30ms from EMEA, 100/150ms from AMER, and 250/300ms from APAC: as if from all of those countries you were being routed to the Amsterdam datacenter.
What I’m seeing in terms of latency is confirmed by analysing reverse lookups of routers found in the different paths to Telegram: in my trace from Australia the last visible hop is et3-1-2.amster1.ams.seabone.net (notice that “ams”), most of the traces from US are landing on xcr1.att.cw.net (195.2.1.14) which 1 millisecond away from my lab in Amsterdam and a couple of samples from US and Canada are running all the way up to ae-2-3201.ear3.Amsterdam1.Level3.net, which is self-explaining.
Important to highlight, there are no outliers: I couldn’t find a single example of very low latency from APAC / AMER, that would have proved the existence of a local point of presence. A summary of my tests in the table below:
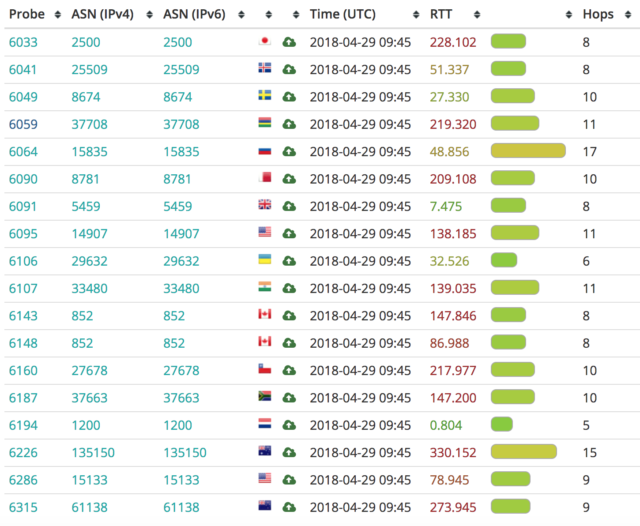
To get the full picture, I decided to dig into AS62041 main upstream carriers (CW AS1273, TI Sparkle AS6762, Level3 AS3356) and see how they were handing over internet traffic to Telegram.
Turns out, CW is always preferring the path to xcr1.att.cw.net/195.2.1.14 (tested from some locations across the world), our little router-friend in Amsterdam. TI Sparkle always lands on amster1.ams.seabone.net and Level3 only has paths to ear3.Amsterdam1 (tested from Asia and US). Level3’s BGP communities are interesting: routes are tagged as “Europe Backbone” and “Level3_Customer Netherlands Amsterdam”:

Telegram is also peering with Hurricane Electric (AS6939): their routers in US, JP, AU have a next hop of ams-ix-gw.telegram.org/80.249.209.69 for 149.154.164.0/22. That hop seems to be Telegram’s AMS-IX facing router, and the IP is definitely part of AMS-IX:
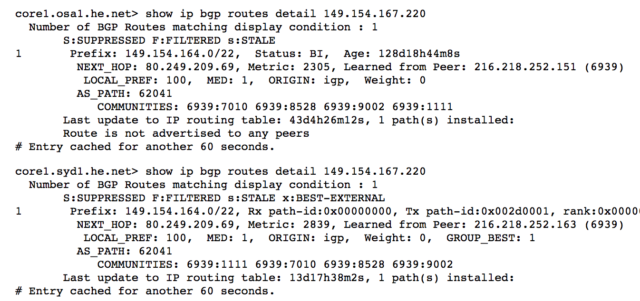
As said in the opening, there are definitely more questions than answers in the article. It’s as if there was no Telegram infrastructure outside Amsterdam, and over there it was running in a single datacenter. This would explain why users across the world are seeing an outage that should only affect EMEA and close areas, and why Telegram is not taking steps to reroute users to another datacenter/location during the failure in AMS.
Am I missing something very obvious? Please let me know!
UPDATE: With the help of some friends and random people, I found out more details. Find them (with -ongoing- updates) in the dedicated post.

 (per non dimenticare: il load balancing manuale delle Elezioni 2011)
(per non dimenticare: il load balancing manuale delle Elezioni 2011)