Telegram’s infrastructure and outages. Some updates.
This post is meant as an (ongoing) sequence of updates to the previous one about Telegram’s outages in March and April 2018. Please read it here first.
Last updated: April 30th, 6:00 AM UTC
UPDATE 1
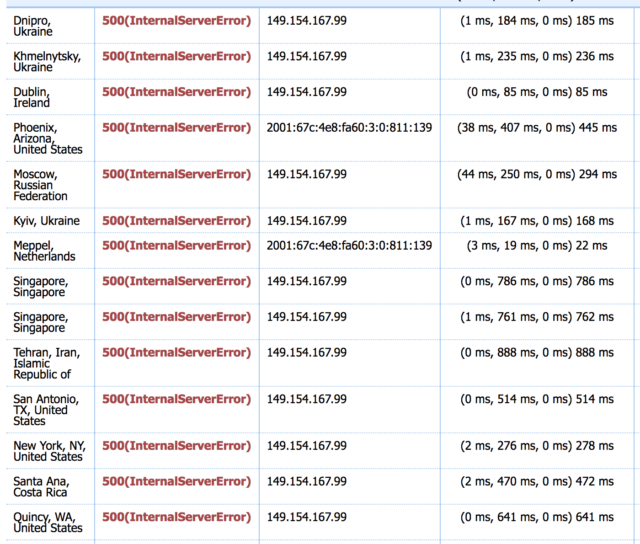
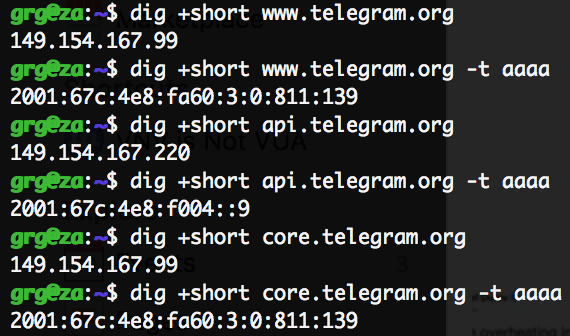
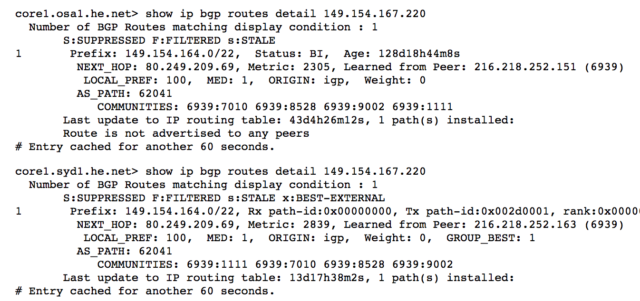
With the help of a friend (and his own HowIsResolved), we managed to confirm that for most open resolvers worldwide (25k+ tested) api.telegram.org is showing up as 149.154.167.220. Only outliers seem to be China (resolving as of now as 174.37.154.236) and Russia (85.142.29.248).
UPDATE 2
During my analysis this morning I created a new Telegram App, and the (only) suggested MTProto (the Telegram protocol) server was 149.154.167.50. This falls into the IP range analysed above, and seems to be solely located in Amsterdam.
Kipters was so kind to review and help me notice that this server is not used for real “data” communication, but just for a “discovery” API call (help.getConfig method) which will return the list of servers that will have to be used for sending messages. We are currently still in process of comparing ranges received across the world, but in the best case scenario (ie: they are spread over multiple geographic locations) this would mean that there is still a single point of failure in the hardcoded “directory” server.
UPDATE 3
What I found in the previous note was “too weird to be true”, so I went ahead and kept digging into TDLib and the official Desktop and Android Apps, to confirm wether they were bootstrapping a session beginning from a single MTProto endpoint or not.
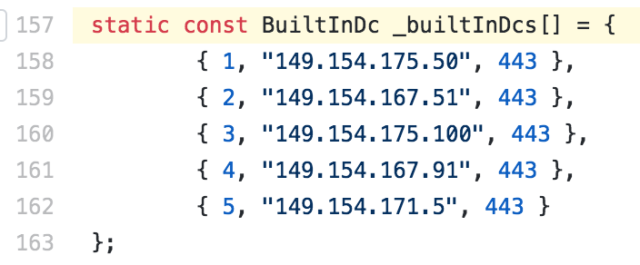
Fortunately, turns out this is not the case (relevant snippets for TDLib, Desktop, Android Apps): both of them contain, hardcoded, in addition to endpoints in the range 149.154.167.0/24 (Amsterdam, AS62041), endpoints in 149.154.175.0/24 (Miami, AS59930) and 149.154.171.0/24 (Singapore, AS62014).
Sounds like we should look into different reasons why many users worldwide outside of EMEA had issues today (or wait for an official, detailed post mortem if it will ever come): there are many, from broken dependencies to weird cases of mis-routing.
Some areas are left to explore (feel free to share your ideas if you have any): why third party apps don’t have access to the whole list of “initial” MTProto endpoints, and are pushed to use only a single, non redundant one? Why the main website and api.telegram.org (mainly used for bots I think) are based off a single location?
UPDATE 4
Telegram Web (https://web.telegram.org/) seems to be single-homed in Amsterdam too. As I haven’t had the opportunity to test during the outage, I don’t know whether it has been failed over somewhere else or not.
UPDATE 5
According to the official documentation, users (registered by phone number) are located off a single datacenter, picked at signup time based on geographical proximity: “During the process of working with the API, user information is accumulated in the DC with which the user is associated. This is the reason a user cannot be associated with a different DC by means of the client.”
They are only moved if they keep connecting from a remote location for a prolonged period of time (ie: you permanently relocate to another continent): this might explain why there seem to be no failover scenario and 12+ hours outages are happening.
(Thanks to adjustableneutralism from Reddit for flagging)


 (per non dimenticare: il load balancing manuale delle Elezioni 2011)
(per non dimenticare: il load balancing manuale delle Elezioni 2011)