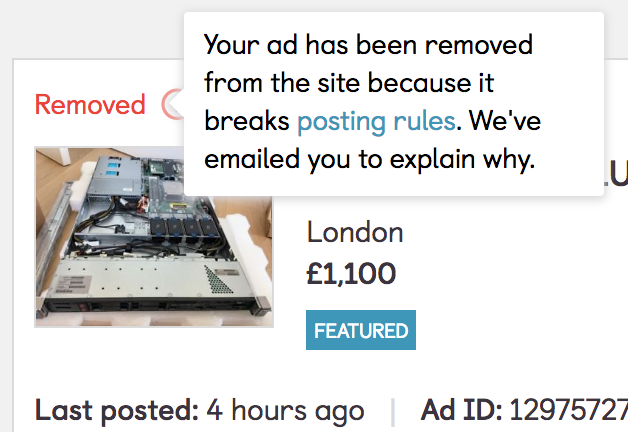
Exactly one year ago today I was sitting in a room in Amazon’s London Holborn office, attending the New Hire induction and waiting for my manager to pick me up and introduce me to the rest of the Technical Account Managers team.
It has been one year already – it’s about time to tell my story, and share my experience in this (amazing) reality.

(this is me at this year’s London Summit, looking for something, somewhere)
Looking back at the first year (or, in Amazonian terms: “those first 365 day one’s.”), I can easily highlight a few different phases. Here they are, in a more or less chronological order.
—
Phase 1: “lost” (in an hexagonal office)
Technical Account Managers (TAM) spend a lot of time with customers, and only drop into the AWS office when required. As a new starter this can be a little daunting, especially when trying to get set up – configuring your mobile, using the vast array of internal tools you have at your fingertips and the simple things, like finding the toilet.
The good news is: everybody is always happy to help you. Literally: everybody. In my first days I had phone calls with most of my team mates, shadowing sessions in front of customers, and even asked a mix of random people in the office for various kinds of help: they always guided me, as if it was a single, big family and that helped me, and I never really felt lost (yeah, I know, but it looked as a good title for this chapter…).
(about the toilet, if you’re wondering: I realised that as our office was hexagonal – or kind of -, everything was “straight on and then on the left”)
I’ll skip phase 1.5, the official training: we spend about two to three weeks in classes with Support Engineers before getting hands on with the day to day job. The training is what you’d expect from training, but it provides a great opportunity to meet and learn from tenured colleagues. This is also when I personally went from getting lost in the London office to getting lost in the Seattle campus (every. single. time.).
Phase 2: the ramp up (aka: “OMG I don’t know anything”)
The ramp up that comes after the training is exciting: you’re back, you’ve had 2/3 weeks to try to learn as much as possible and after three weeks of training, you think you know what you are doing – you’ve learnt the theory, you know how to use the tools, you think you know what to do when, and you’re ready to get on with it.
In theory.
What you realise at this point is that yes, it’s true, and you’re working with Amazon Web Services. If you work with cloud, you hear this name daily, and becoming part of it doesn’t simply feel real for a while.
One of the first matters I understood was that the only thing I was bringing with me in AWS was my brain: your past experience can definitely help, but Amazon is so different from other companies that you have to learn, literally from scratch, almost everything. If you’ve been hired it’s because you share the mindset, so it’s not hard and it’s not an obstacle, it’s just something to keep in mind.
The main differences? First, and by far, is our “Customer Obsession”. We obsess over our customers, and not over our technology: every discussion we have ends up focusing what’s best for our customers, and how we can improve their experience. We work every day making sure we help them doing what’s best for their platforms – not for us – and we spend our time listening to them and trying to figure out how to make their life easier.
The second one is definitely what’s summarised in our “Everyday is Day One” motto, which is much more tangible than you would expect from something that is written on every wall in an HQ. Our customers and us are moving so quickly that you must always be ready to wake up and start as if you were in a completely new world. You learn new things daily and the technology you were using / evangelising three months before could not be the best one for a given use case anymore.
This is all about change and how it becomes part of your daily routine.
Phase 3: the First Customer
After a few months you’re ready to onboard your first customer. I had spent some time shadowing and helping a more tenured colleague, and in November I was ready for onboarding my first “very own” account.
At that point in time I was confident on my daily tasks, had already had to deal with critical situations, and everything was looking good. But the first customer you onboard onto AWS Enterprise Support is just different: you’re starting a journey together, with some pre-defined goals and some others that will eventually show up.
It’s journey of change, a journey toward continuous improvement and optimisation.
It’s just matter of weeks, and you will start knowing your customer’s team members by first name, and recognising who’s logging a support case just by looking at their writing style.
Yes, that’s a very close relationship: some of my colleagues love to say that we work for Amazon, but on behalf of our customers.
Phase 4: the first event
You don’t really feel part of the customer’s team until you go through your first event. An event could be anything, from a planned traffic spike or feature launch, to, ehm, yes, an unplanned downtime.
Let’s pick a feature launch: it’s something big, the customer’s development teams have been working for months on it, the marketing team is heavily pushing and the operational teams do have a single focus, making sure everything will work smoothly.
This is where our teams become glued together with the customer’s: we share a goal, we share a focus, we setup “war rooms” and make sure everything is in place and properly architected for when the big day arrives. The TAM acts here as a customer facing frontman for an army of Support Engineers, Subject Matter Experts, Service Team Engineers, and many more – and during this kind of events, everyone comes together.
And then it happens – detailed and obsessive planning ensure everything works smoothly and meets expectations, leaving plenty of time to celebrate – and to realise that none of this would be possible without the super close relationship we develop with our customers.
Phase 5: personal development
This is not really a phase (mainly because it never ends), but after you’ve been in the company for 6/8 months you begin having really clear ideas on how things work, where you want to go and what you want to do.
AWS is a world of opportunities, for any kind of person: in this first year I joined a team which is helping our customers with the migration of strategic workloads and presented at the AWS Summit in London.
I’m currently trying to decide what to target next.
Phase 6: retrospective
As said, technology is evolving quickly, and so are we and our customers. When you reach the one-year mark, you try to look back and this is when you really understand where you used to be, and where you are now.
Where your customers were, and where they are now: the distance they have most likely covered in a single year looks unbelievable.
Phase 7: writing a blog post about your first year
Come on, I’m just joking.
—
Time to wrap up: I’m enjoying my new working life, my team, my mentor(s), my manager(s) and the extended Enterprise Support team. I have the opportunity every day to work with exciting customers, to actually be part of my customer’s teams and to experience the latest innovations first hand.
There is a question I get asked a lot, especially from people who know my background: do I miss being hands on, had to do with operations? Not really. First, we have time and business needs for testing and using any new product we launch, so I still spend some time actually “playing” with stuff. Second, despite the name, this role is super-technical – we get to see a lot of operations, development and devops.
If you are reading this and looking for a new and interesting challenge, or would like to consider joining the AWS team, then get in touch.
Giorgio
Like this:
Like Loading...