Internet si basa su standard aperti, che vengono definiti attraverso discussioni “pubbliche” tra tecnici. Il meccanismo è semplice: per prima cosa, un gruppo di persone studia, disegna uno “standard”: decide che qualcosa debba essere fatto in un certo modo perchè pensa quella sia la soluzione migliore.
La seconda fase consiste nel pubblicare una RFC, Request for Comments, in modo che gli altri interessati possano leggerla e come il fantasioso nome suggerisce, commentarla. La proposta viene modificata per coprire le necessità di tutti e correggere eventuali errori e poi diventa “standard de facto”. Standard non imposti, che tutti rispettano perchè altrimenti sarebbe il caos più totale. E’ così che si va avanti da 30 anni, senza che mai il meccanismo abbia mostrato debolezze. E’ un pò lo stesso funzionamento dei semafori, niente impedisce a me di decidere che io passo quando è rosso e mi fermo quando è verde, ma non posso farlo perchè so che se anche uno solo si comportasse così tutto il sistema anrebbbe in panico.
Una importante Request for Comments, la RFC 1918, datata Febbraio ’96, ha stabilito che le classi di IP utilizzabili liberamente (senza richiederne l’assegnazione da parte dell’autorità) nelle reti private fossero:
192.168.0.0/16
172.16.0.0/12
10.0.0.0/8
Nell’Aprile 2012 a queste è stata aggiunta la classe 100.64.0.0/10, per i “Carrier Grade NAT” (RFC 6598).
Diverse entità, probabilmente allergiche agli standard, si sono appropriate di classi di IP senza averne titolo. A memoria, ricordo Fastweb, che usava (usa?) le classi 1.0.0.0/8, 2.0.0.0/8, 5.0.0.0/8 (and counting) per l’indirizzamento interno, H3G che ad oggi usa la 1.0.0.0/8, Hamachi e OpenVPN (nella versione a pagamento) che assegnano IP interni ai client dalla classe 5.0.0.0/8, Remobo, software simile ai precedenti che si è appropriato della classe 7.0.0.0/8 e così via.
L’ICANN, sapendo che queste classi erano di fatto utilizzate, pur non avendo intenzione di regolarizzarle (erano e sono utilizzate in modo assurdo, senza motivazione tecnica, sarebbe stato solo un enorme spreco di risorse) ha ritardato fino all’ultimo momento la loro assegnazione. Adesso però gli IP stanno finendo, e l’autorità per l’assegnazione è costretta ad utilizzarli.
Se un determinato ISP usa una classe in modo irregolare e questa viene assegnata, si ritroverà con un conflitto nel routing della sua rete interna: dovrebbe far “uscire” i pacchetti dalla sua rete per raggiungere il reale proprietario di quegli IP ma se lo facesse renderebbe irraggiungibili i suoi host interni che utilizzano (in modo, ci tengo a ricordarlo, illecito) tali indirizzi IP, creando disservizi. La questione è spiegata (anche) qui, in inglese.
A questo si aggiunge il problema del “Bogon Filtering“. Il bogon filtering è un semplice quanto effettivo metodo per filtrare pacchetti spoofed (attacchi, in altre parole): questa tecnica consiste nel filtrare direttamente alla frontiera della rete i pacchetti provenienti da IP non pubblici o da classi di IP non assegnate. Il motivo è chiaro: se gli IP che inviano quei pacchetti non sono stati assegnati a nessuno, la sorgente indicata non è quella reale e quindi si tratta di pacchetti “maligni” o di errori di configurazione. La logica conseguenza è che se una classe viene assegnata e l’ISP non aggiorna i suoi filtri continuerà a bloccarla credendola inutilizzata, rendendo ai suoi utenti impossibile raggiungere gli host remoti appartenenti a quella classe.
Alcuni ISP usano o hanno usato inoltre le classi non allocate per delle prove tecniche, annunciandole nelle tabelle di routing mondiali. Qualche annuncio “residuo”, al suo sovrapporsi con quelli nuovi e “leciti”, potrebbe quindi creare ulteriori conflitti nel routing delle nuove classi.
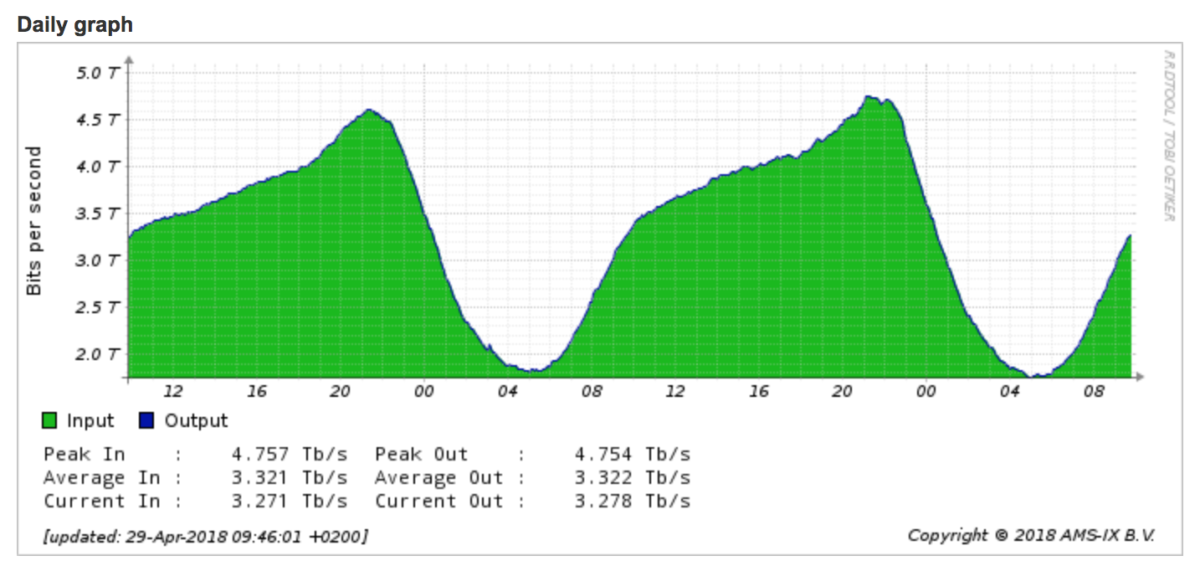
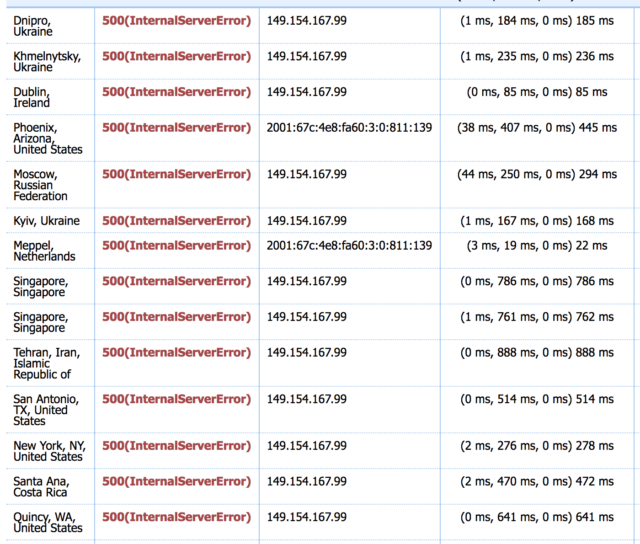
L’autorità per la registrazione si impegna a segnalare con adeguato anticipo le classi che stanno per essere assegnate, ma non tutti sembrano leggere queste pagine, come mostra questo grafico:

Si nota infatti che quasi il 10% degli AS mondiali non è in grado di raggiungere le classi indicate. Un grandissimo problema.
Temevo che qualcosa prima o poi sarebbe successo, e un messaggio di Marco questa notte me l’ha confermato: da rete Fastweb non si riescono a raggiungere IP della classe 5.0.0.0/8, assegnata in queste settimane a grossi ISP come Softlayer, Hetzner, OVH. Ne parlano qui, su HostingTalk.it. Leggendo poi questo topic su WebHostingTalk, scopro che il problema non è limitato a Fastweb, ma si verifica anche da altri ISP.
Ecco un traceroute da rete Fastweb verso un IP di Softlayer:
C:\Users\User>tracert 5.10.64.1
Traccia instradamento verso 5.10.64.1-static.reverse.softlayer.com [5.10.64.1]
su un massimo di 30 punti di passaggio:
1 <1 ms <1 ms <1 ms 192.168.1.1
2 226 ms 17 ms 17 ms EDIT
3 17 ms 16 ms 17 ms EDIT
4 492 ms 35 ms 17 ms 10.251.149.201
5 122 ms 16 ms 16 ms 10.251.144.25
6 47 ms 112 ms 164 ms 10.251.145.1
7 537 ms 477 ms 250 ms 10.251.149.186
8 351 ms 17 ms 17 ms 10.3.136.189
9 41 ms 17 ms 20 ms 10.3.128.41
10 135 ms 16 ms 471 ms 10.254.9.230
11 69 ms 20 ms 21 ms 10.254.12.21
12 150 ms 20 ms 20 ms 10.254.12.6
13 125 ms 24 ms 417 ms 89.97.200.66
14 * * * Request timed out.
15 * * * Request timed out.
C:\Users\User>
Carino. Ecco cosa succede quando un grande ISP non rispetta gli standard che dovrebbero essere la base del suo lavoro. Crea un danno sia ai suoi utenti, che non riescono a raggiungere una parte di internet, sia alle entità a cui sono stati assegnati gli IP che lui usa in modo illecito.
Cosa fare quindi se vi trovate in una situazione simile, cioè se non riuscite a raggiungere alcuni IP (e quindi server)? Sarebbe totalmente sbagliato e inutile contattare il proprietario di quel nodo (server), perchè non ne ha colpa nè ha modo di risolvere il problema. La soluzione è chiamare il call center di Fastweb, bombardarlo, intasarlo giorno e notte ripetendo la segnalazione, perchè è una loro mancanza: offrono un servizio incompleto e non rispettano le RFC. Si tratta, a tutti gli effetti di un disservizio, quindi non esitate e soprattutto non accettate risposte che non contengano una promessa di immediata risoluzione del problema.
La parte più bella sta nel fatto che l’autorità (ICANN/RIPE) ha la possibilità di revocare le assegnazioni fatte a LIR (provider) che utilizzano senza averne titolo classi assegnate ad altri, come Fastweb sta facendo in questo momento. Se le segnalazioni all’autorità diventassero consistenti, Fastweb potrebbe rimanere completamente in mutande, senza più nemmeno un IP per far uscire i suoi utenti su internet. Meglio. Più IP disponibili per chi rispetta le regole.
E se invece siete voi proprietari di un server non raggiungibile da alcuni ISP? Anche qui, deve esser chiaro che non avrebbe senso (e non sempre sarebbe fattibile) richiedere a chi ve lo ha assegnato un nuovo IP “pulito”, o ritenere il vostro provider responsabile del problema.
Segnalate a ICANN/RIPE (tramite questo form) la violazione, perchè, come dicevo poco fa, Fastweb potrebbe pagarla davvero molto cara. Contattate voi stessi Fastweb, sia attraverso i canali di supporto ufficiali sia attraverso i contatti tecnici (reperibili tramite il RIPE), e, per finire, chiedete ai vostri utenti che stanno subendo un disservizio di fare lo stesso, chiedete che riportino il problema e che pretendano sia risolto in tempo reale. E’ davvero importante muoversi, perchè Fastweb sta danneggiando tutti.
Non sono un avvocato, ma immagino che sia i clienti Fastweb tagliati fuori da internet sia i proprietari dei server irraggiungibili possano chiedere pesanti risarcimenti al provider. E chissà che non si muova anche il CODACONS, che farebbe una delle prime mosse giuste e tecnicamente sensate della sua vita.
I LIR / AS a cui fossero stati assegnati gli IP “sfortunati”, potrebbero poi “convincere” gli ISP che creano loro tali problemi di raggiungibilità in diversi modi, più o meno leciti ma tutti visti negli anni: bloccando i peering, rendendo le loro reti completamente inaccessibili dagli ISP incriminati, droppando pacchetti a destra e a manca, in modo che i clienti di questi ultimi, imbestialiti, aumentino la pressione.
Lo so, da tecnico non dovrei consigliare di “spammare” un call center e ripetere le segnalazioni, di solito non si fa così. Ma quando degli standard vengono violati tutto diventa lecito. “L’hai violato? Adesso assumi 250 persone per non far crollare il call center sotto le segnalazioni, e PEDALI, perchè non è così che si lavora.”.
Concedetemi un commento altamente tecnico nei confronti di Fastweb: “AHAHAHAHAHAHAHAHAHAHAHAHAH”.
Ricordatevi quindi: seppellite di segnalazioni chi ha sbagliato e chi vi sta veramente creando questo disservizio, non prendetevela con chi ha rispettato le regole e non ha nessuna colpa. Telefonate, telefonate e telefonate ancora, e quando siete stanchi fate chiamare anche i vostri parenti dalle altre stanze della casa. E il giorno dopo richiamateli, per chiedere aggiornamenti o anche solo per salutarli.
Se volete che il problema venga risolto, insomma, sostituite per i prossimi giorni il numero della vostra ragazza in rubrica con il numero del loro callcenter.
Concludo con un meritato #EPIC FAIL per Fastweb. Ovviamente non sono loro cliente. Non vorrei diventarlo neanche se mi pagassero loro stessi per usare i servizi che offrono. Però, ho ordinato ieri un server da Softlayer e rischio di ritrovarmi un IP appartenente alle classi di cui abbiamo parlato fino ad ora. Con le conseguenze di cui abbiamo parlato fino ad ora.
UPDATE: E’ quasi l’una di notte, del 19 Maggio, e ho appena visto il primo traceroute andare correttamente a destinazione da rete Fastweb. Tutti gli IP di test che avevo usato, Softlayer, OVH, Hetzner, vengono ora correttamente ruotati. Un traceroute in memoriam:
Traccia instradamento verso 5.10.64.1-static.reverse.softlayer.com [5.10.64.1]:
1 <1 ms <1 ms <1 ms 39.235.148.254
2 30 ms 49 ms 27 ms 10.128.96.1
3 49 ms 29 ms 29 ms 10.3.231.210
4 32 ms 32 ms 34 ms 10.251.143.209
5 30 ms 27 ms 28 ms 10.251.138.27
6 25 ms 27 ms 29 ms 10.251.139.1
7 32 ms 27 ms 29 ms 10.251.143.194
8 37 ms 32 ms 27 ms 10.3.134.241
9 32 ms 27 ms 28 ms 10.3.128.46
10 33 ms 28 ms 29 ms 10.254.11.69
11 36 ms 29 ms 35 ms 10.254.1.77
12 33 ms 95 ms 41 ms 89.97.200.62
13 28 ms 29 ms 38 ms 26.26.127.54
14 31 ms 37 ms 39 ms 93.55.241.54
15 37 ms 28 ms 29 ms 26.26.127.69
16 38 ms 39 ms 38 ms 93.57.68.21
17 30 ms 38 ms 39 ms 93.57.68.5
18 35 ms 36 ms 29 ms if-5-0-0.core1.RCT-Rome.as6453.net [195.219.163.9]
19 59 ms 58 ms 59 ms if-11-0-0-0.tcore1.PYE-Paris.as6453.net [80.231.154.41]
20 56 ms 59 ms 75 ms if-2-2.tcore1.PVU-Paris.as6453.net [80.231.154.17]
21 57 ms 63 ms 76 ms xe-6-3.r03.parsfr01.fr.bb.gin.ntt.net [129.250.8.177]
22 84 ms 58 ms 59 ms ae-1.r21.parsfr01.fr.bb.gin.ntt.net [129.250.2.224]
23 79 ms 62 ms 75 ms as-4.r22.amstnl02.nl.bb.gin.ntt.net [129.250.3.84]
24 64 ms 67 ms 69 ms po-1.r01.amstnl02.nl.bb.gin.ntt.net [129.250.4.71]
25 64 ms 115 ms 62 ms ae11.bbr01.eq01.ams02.networklayer.com.64.20.81.in-addr.arpa [81.20.64.50]
26 88 ms 61 ms 58 ms ae5.dar01.sr01.ams01.networklayer.com [50.97.18.237]
27 65 ms 58 ms 65 ms po1.fcr01.sr01.ams01.networklayer.com [159.253.158.131]
28 72 ms 62 ms 58 ms 5.10.64.1-static.reverse.softlayer.com [5.10.64.1]
Notate gli hop numero 1, 13 e 15. Il primo usa un IP appartenente ad una classe assegnata ad APNIC, che potrebbe entrare in uso a breve creando nuovi problemi di raggiungibilità. Il 13 e il 15 fanno parte di una classe assegnata al Dipartimento della Difesa americano. Inutile ripeterlo, Fastweb non ha titolo per usare nessuna di queste classi.
Com’è che si diceva del lupo?
Giorgio