[questo articolo è la versione aggiornata e rivista del precedente articolo che era a sua volta la versione rivista e curata di un mio thread inizialmente pubblicato su Twitter]
A volte succede che siti web a basso traffico per la maggior parte della loro esistenza divengano improvvisamente critici per la sopravvivenza dell’umanità.
Questa settimana è stato il turno del sito del Ministero della Salute (salute.gov.it), diventato importante a seguito dell’arrivo del COVID-19 (Coronavirus) in Italia, e collassato sotto il peso dei cittadini che cercavano di informarsi.
Da cittadino non posso che pensare il Ministero non ci abbia fatto una bella figura: in casi come questo l’accesso alle informazioni può veramente prevenire il panico (e/o salvare vite). Da persona (dicono) competente nel settore devo riconoscere che pur essendo la scalabilità delle piattaforme web uno dei problemi più complessi dell’informatica, nel caso di siti informativi (in sola lettura) gestire i picchi di carico diventa estremamente semplice (e veloce).
Ecco quindi un vademecum che spiega come reagire nel caso in cui vi troviate in una situazione simile e doveste riportare online con molta fretta un sito sotto un carico talmente alto da non riuscire nemmeno a collegarvi all’infrastruttura.
Il primissimo passo (contro intuitivo) è quello di chiudere gli utenti fuori dal sito e far si voi siate gli unici a poterlo raggiungere. Il modo migliore è bloccare le porte HTTP/HTTPS sul firewall: se il numero di connessioni è molto elevato, un semplice deny sul frontend potrebbe non bastare.
Fatto questo, procedete con il ripristino del funzionamento del sito per poterci lavorare dall’interno della vostra rete: spesso un riavvio dei componenti (database, application server, frontend) è sufficiente. Controllate che le partizioni in cui vengono scritti file temporanei, sessioni e log non siano piene: in base alla situazione (e al software specifico) potrebbe avere senso rimontarle temporaneamente in /dev/null per escludere una fonte di possibili problemi.
Date anche uno sguardo alla configurazione per controllare non ci siano inutili colli di bottiglia, come limiti troppo stringenti al numero di connessioni verso il database o verso l’application server: in una simile situazione potrebbero creare più problemi che benefici.
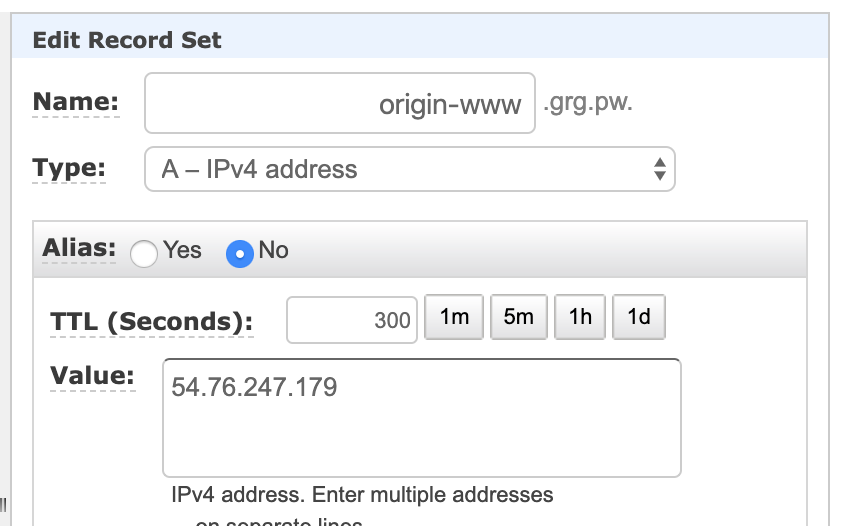
Sostituite l’indirizzo IP esterno del frontend: dobbiamo assicurarci che non sia più raggiungibile direttamente dagli utenti una volta riaperto il firewall, motivo per cui aggiungere un nuovo indirizzo in alias non è sufficiente e quello precedente va completamente rimosso.
Create anche un record DNS temporaneo che punti al nuovo IP (ad esempio origin-www.grg.pw). Già che ci siete, assicuratevi che il TTL del vostro hostname principale sia basso, a 300 secondi o meno.
Configurate una CDN: create una distribuzione/vhost usando l’hostname primario del vostro sito web (www.grg.pw) che abbia come origin/backend l’hostname temporaneo creato poco prima. Mi riferirò ad Amazon Cloudfront perchè a differenza di altre è disponibile in self provisioning
In questo scenario ci sono alcuni valori di configurazione estremamente critici: prima di tutto, alzate l’origin timeout ad almeno 60 secondi.
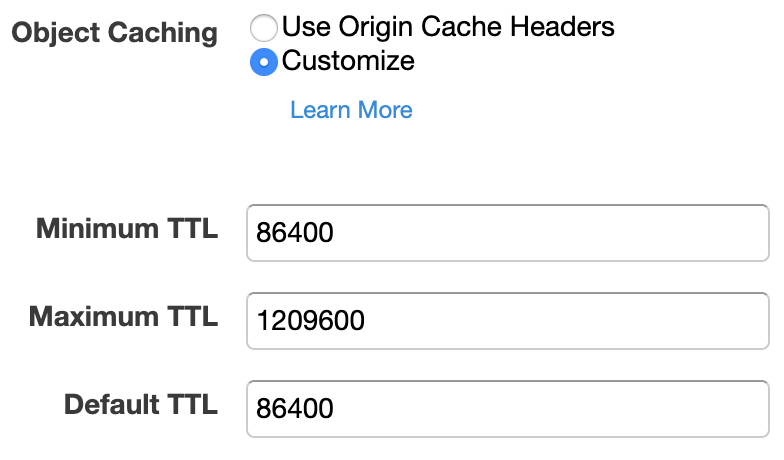
Configurate poi la CDN perchè ignori gli header di caching (non) impostati dal vostro CMS e forzi invece un default e un minimum TTL ragionevolmente alti (nel mio esempio 24 ore).
[NB: questa configurazione non sarebbe ottimale in un normale ambiente di produzione, ma nello scenario sopra descritto la priorità è massimizzare la probabilità che i contenuti finiscano in cache, e che poi ci rimangano]
Disabilitate il forward dei cookie e degli headers HTTP: questo aumenterà la resa delle cache (ma romperà tutte le funzioni di personalizzazione e il login). Il forward delle query string è un tema leggermente più spinoso e richiede conoscenza del CMS: impostatela in modo che venga inoltrato il minimo necessario alla generazione delle pagine (se le vostre URL non includono query strings, disabilitatelo).
Se il sito in questione ha un’area amministrativa (diciamo /wp-admin/), rendete l’intero path inaccessibile al pubblico: potete farlo sia con una eccezione nella configurazione della CDN stessa o direttamente sul vostro frontend. Questo passaggio è importante perchè con la configurazione che stiamo usando la CDN potrebbe inserire in cache (in sola lettura, ovviamente) anche le pagine amministrative e renderle disponibile a tutti gli utenti.
Ci siamo quasi. Il prossimo passo è configurare il vostro firewall perchè accetti solo connessioni provenienti dalla CDN. Se vi risulta troppo complicato se ne può temporaneamente fare a meno (ricordiamo che il nuovo indirizzo IP del frontend è sconosciuto agli utenti, così come il record DNS temporaneo che abbiamo creato).
Potete ora procedere con l’aggiornamento dei record DNS del vostro dominio principale perchè puntino alla CDN e non più direttamente al server.
Il vostro portale tornerà lentamente online, con la propagazione dei nuovi record.
DISCLAIMER: quella qui descritta è una configurazione di emergenza, da usare nei casi in cui riportare online nel minor tempo possibile un portale contenente informazioni critiche è la priorità. Dovrete eseguire invalidation a mano ogni volta che i contenuti vengono aggiornati, e potete stare certi che qualche funzione del portale si romperà. Se avete usato questa guida, è importante pianifichiate l’implementazione di una configurazione adeguata il prima possibile.
Per ogni necessità, mi trovate su Twitter.